


 15 minutes without single line of code no code ETL solution
15 minutes without single line of code no code ETL solution 
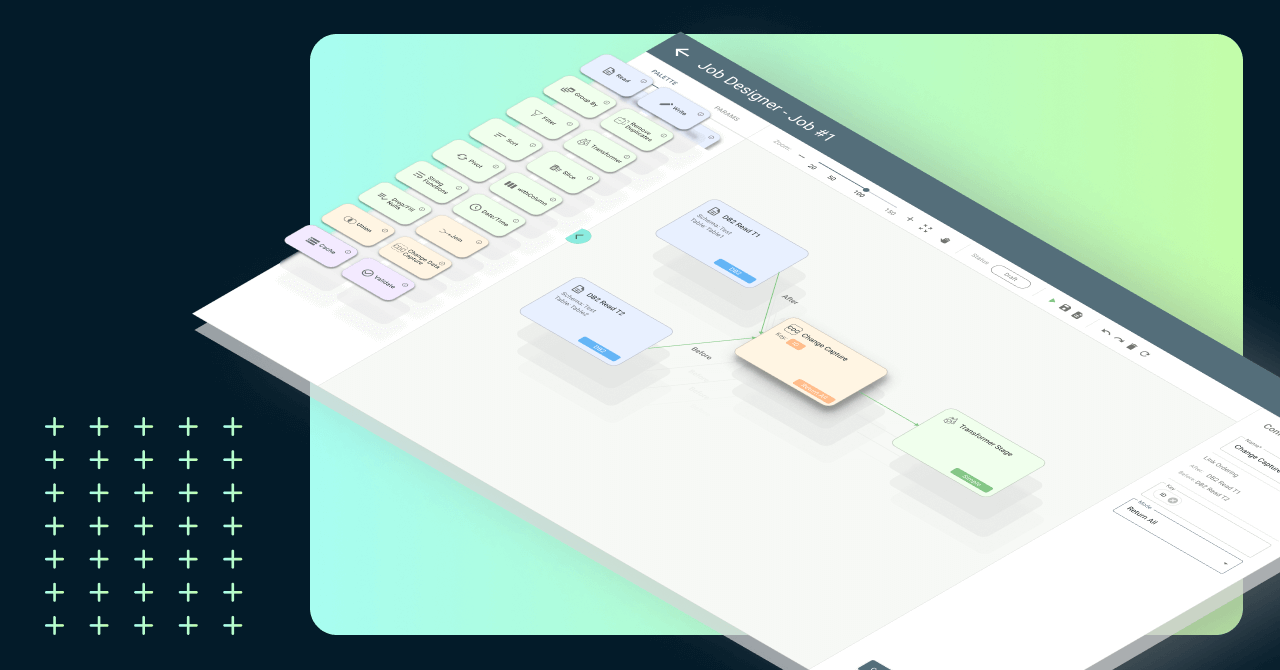

On-premise and cloud availability
Runs on any Kubernetes cluster on-premises or cloud, ensuring multi-cloud compatibility

Spark processing engine
The power of the Spark processing engine available with no single line of code

Stage palette with all main operators features
Stage palette featuring tens discrete data transformation functions

Unlimited scalability
Virtually unlimited horizontal scalability

External invoking of pipelines
Ability to externally invoke Visual Flow pipelines using POST requests

Deployment on any Kubernetes cluster
Ability to deploy your ETL/ELT on any Kubernetes cluster anywhere, once designed
Visual Flow benefits that our  users highlight
users highlight

Saving money leveraging open source solution

The migration to Visual Flow allowed us significantly reduce maintenance cost.
During the development process, it was necessary to add new features to Visual Flow to satisfy client’s business needs. Finally, it was implemented successfully, what allowed us fully migrate the existing ETL process to Visual Flow.
CTO of IT company

Improved productivity and scalability

Visual Flow team helps us in supporting clinical and medical research to empower clients’ healthcare capabilities and to provide cutting-edge services to patients all around the world. We created new frontend for easy mapping on the base of Visual Flow. Now its GUI allows client’s business users to aggregate data from multiple sources, integrate it and prepare for further analysis.
CTO of US based IT company

Unlimited scalability
With Visual Flow my team is successfully working on processing permanently growing volumes of data due to unlimited scalability and parallel processing capabilities of containerized Spark jobs.
Lead ETL Developer
Saving money leveraging open source solution
The migration to Visual Flow allowed us significantly reduce maintenance cost.
During the development process, it was necessary to add new features to Visual Flow to satisfy client’s business needs. Finally, it was implemented successfully, what allowed us fully migrate the existing ETL process to Visual Flow.
CTO of IT company
Improved productivity and scalability
Visual Flow team helps us in supporting clinical and medical research to empower clients’ healthcare capabilities and to provide cutting-edge services to patients all around the world. We created new frontend for easy mapping on the base of Visual Flow. Now its GUI allows client’s business users to aggregate data from multiple sources, integrate it and prepare for further analysis.
CTO of US based IT company
Unlimited scalability
With Visual Flow my team is successfully working on processing permanently growing volumes of data due to unlimited scalability and parallel processing capabilities of containerized Spark jobs.
Lead ETL Developer

Visual Flow is a low-cost, low-code, open-source product. Its portability, flexibility, and  multi-cloud capability 'makes it the most powerful of all ETL solutions for businesses
multi-cloud capability 'makes it the most powerful of all ETL solutions for businesses





















We combine the most powerful technologies and put them under the  drag-and-drop interface of the Visual Flow ETL solution platform to simplify complex development while keeping engineering excellence
drag-and-drop interface of the Visual Flow ETL solution platform to simplify complex development while keeping engineering excellence
Simplification for the sake of increased productivity
Creative freedom: use Visual Flow with no code, low-code or custom code
Ripping all benefits of the best open-source solutions
Scaling at the pace of the data — not your human resources
Dive deeper into Visual Flow and feel free to co-create








Frequently asked questions
Absolutely! Visual Flow low code data engineering is designed for scalability and runs natively within Kubernetes and Apache Spark.
Teams who use Visual Flow can keep their freedom to use custom open source ETL/ELT data integration tools. Visual Flow is based on industry software standards as Kubernetes and Spark, on-premise or on-cloud. Users don’t need to pay for a set of services from the whole platform as AWS or Azure and be limited to use its architecture.
We think about Visual Flow as an open-source tool kit (framework) that can be adapted to your business needs. To learn how the Visual Flow team can help you, contact us at info@visual-flow.com
Our goal is to build an ETL and data pipelines solution that matches your needs. Feel free to contact our team at info@visual-flow.com to learn how to add a new data source.
Visual Flow ETL/ELT data integration solution is supported by a team that consists of experienced data engineers that can do it for you, or you can do it manually since still there is no automated solution for this.
Visual Flow users should know basic SQL, how data sources are used, and how the transformations you would like to apply work.
While Visual Flow is not written in Pyspark, it is possible to execute Pyspark scripts via the container stage of the pipeline entity.
Absolutely! Visual Flow low-code ETL tool is designed for scalability and runs natively within Kubernetes and Apache Spark.
Don’t worry! Simply contact our professional services team for consultation and we’ll help you fix the issue.
To run Visual Flow on your laptop, you’ll need a Kubernetes cluster. You can follow our step-by-step guide on How to Install Visual Flow On-Premises. Alternatively, you can order Visual Flow deployment service from our professional services team.
At Visual Flow, we’re committed to providing powerful, user-friendly ETL tools to help businesses of all sizes. If you have any further questions, please don’t hesitate to contact us.
Contact us