Boost productivity of all data users  with Visual Flow
with Visual Flow
The visual designer provides equal opportunities to the widest number of participants in the data management process
Generative AI streamlines unstructured data processing with LLMs, saving time and boosting data analysis capabilities
Code generation UI in ETL automates coding, reduces errors, speeds up processes, and simplifies ETL tasks
Open-source ETL tool with professional support, democratizing access to technology for everyone—no licensing costs
Develop Databricks Projects Faster
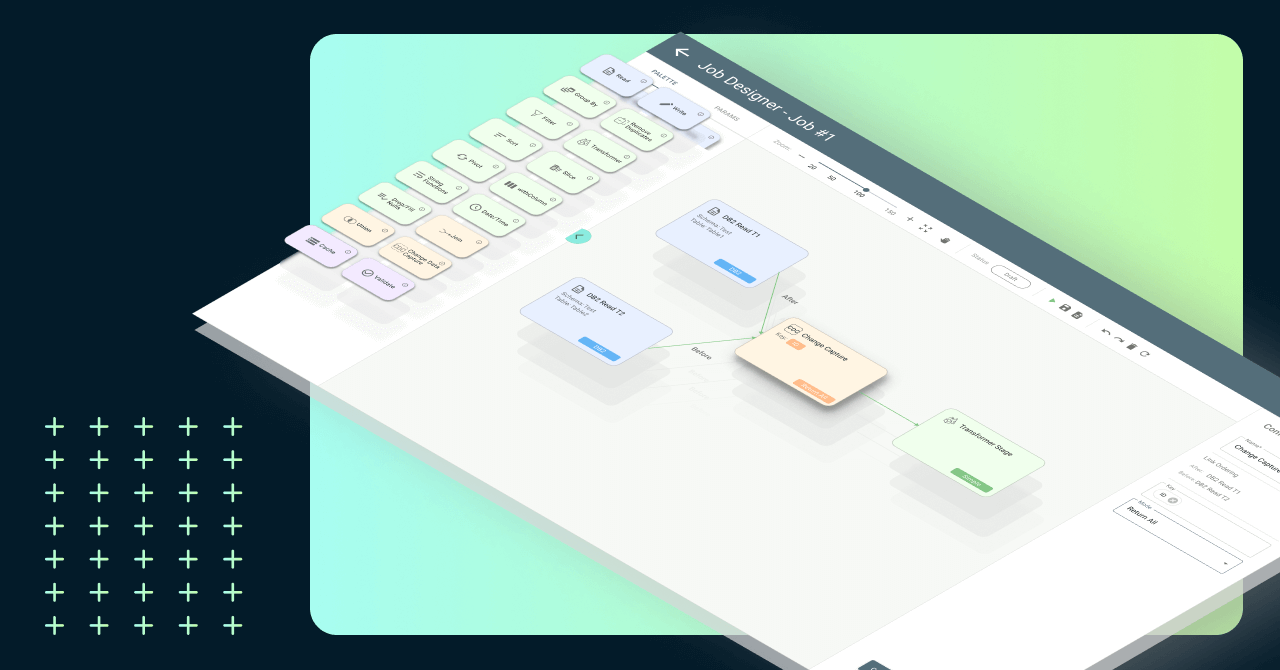
With Visual Flow, you can effortlessly build and deploy data jobs and Databricks ETL pipeline using our visual, intuitive, drag-and-drop IDE. The Databricks declarative ETL framework is highly efficient and user-friendly.

Harness the full power of Spark Scala code for Databricks effortlessly. Visual Flow lets you generate high-quality, efficient, and native Spark Scala code, so you can focus on your data, not the code

Visual Flow is not just about building pipelines; it’s about making development an interactive experience. Develop, execute, and monitor your jobs and pipelines in real-time, ensuring that you’re always in control.

Visual Flow introduces visual elements, designed to simplify complex patterns and ensure scalability for your organization. Create visual elements for sources, natively connect to targets, and improve transformations, all in one place.
Cost-Efficiency: Standardized ETL Jobs on Databricks
At Visual Flow, we understand that cost efficiency is a top priority.
That’s why we’ve made it our mission to help you optimize your ETL jobs on Databricks.
Standardized Code for Cost Savings
Visual Flow for Databricks empowers you to standardize and reuse multiple visual elements across various pipelines, ensuring that each job runs efficiently and consistently. By incorporating Delta Lake on Databricks for your ETL processes, you can further enhance data reliability and performance. By adhering to these standards, you can significantly reduce operational costs without compromising quality.
Predefined UI Elements for Smart Savings
Visual Flow provides predefined UI elements, designed to streamline your ETL processes. These elements simplify your workflow and contribute to cost savings by reducing the time and resources required to manage and run your jobs on Databricks.
Embrace cost-efficient ETL operations with Visual Flow – where standardized code and predefined UI elements pave the way for substantial savings in your Databricks environment.

Build and Manage ETL Pipelines running on Databricks with Visual Flow
Put powerful and native ETL at the fingertips of any data professional.
Our simple, drag-and-drop UI allows you to create high-performing ETL jobs and pipelines.

Accelerate Your Databricks Data Projects with Visual Flow
Visual Flow isn’t just a tool; it’s a catalyst for all your data teams. By using Databricks for ETL, you can seamlessly integrate and operationalize code, automating critical Spark operations through a central platform. Easily operationalize code and automate critical Spark operations through a central platform, ensuring your projects run smoothly and efficiently.

Standardized Code for Cost Savings
Visual Flow for Databricks empowers you to standardize and reuse multiple visual elements across various pipelines, ensuring that each job runs efficiently and consistently. By incorporating Delta Lake on Databricks for your ETL processes, you can further enhance data reliability and performance. By adhering to these standards, you can significantly reduce operational costs without compromising quality.
Predefined UI Elements for Smart Savings
Visual Flow provides predefined UI elements, designed to streamline your ETL processes. These elements simplify your workflow and contribute to cost savings by reducing the time and resources required to manage and run your jobs on Databricks.
Embrace cost-efficient ETL operations with Visual Flow – where standardized code and predefined UI elements pave the way for substantial savings in your Databricks environment.
Build and Manage ETL Pipelines running on Databricks with Visual Flow
Put powerful and native ETL at the fingertips of any data professional.
Our simple, drag-and-drop UI allows you to create high-performing ETL jobs and pipelines.
Accelerate Your Databricks Data Projects with Visual Flow
Visual Flow isn’t just a tool; it’s a catalyst for all your data teams. By using Databricks for ETL, you can seamlessly integrate and operationalize code, automating critical Spark operations through a central platform. Easily operationalize code and automate critical Spark operations through a central platform, ensuring your projects run smoothly and efficiently.