




Table of Content:
Table of Content:


One of the most overlooked components of dealing with large amounts of data is pricing. When a business is first starting out — and likely working with a relatively limited amount of data — that business might not be particularly devoted to finding the most efficient pricing model available.
But as that business grows — particularly in this data-driven era where having access to “good data” is essentially as good as gold — the sheer volume of data that business will be processing can be expected to grow, as well.
In some cases, the enterprise’s data management needs could multiply by one hundred (or more) in less than a month. At that point, the enterprise will be exceptionally concerned with pricing. At the enterprise level, inefficient data management practices could cost millions of dollars per year, or even more.
So, how do you effectively control the cost of data management and transformation?
For most enterprises, this means finding a pricing structure that is compatible with their current needs. Recently, Databricks has become one of the most popular ways to manage the cost of mass data collection, storage, and transformation. In this comprehensive guide, we will discuss some of the most important things to know about the Databricks pricing structure, including how the use of Databricks can potentially help your business.
What is Databricks?
First, let’s start by defining what Databricks actually is.
Databricks is a company that was created by the founders of Apache Spark (an open-sourced, unified analytics engine). The company’s primary product is its digital platform designed for users of Spark who need assistance with cluster management.
In other words, Databricks is a company and platform that makes it easier for relatively larger enterprises to manage large amounts of data while also minimizing (and knowing) their costs. The company has also worked closely and carefully with Microsoft (through Microsoft’s distinct Azure platform) and Amazon (through Amazon’s AWS) to help improve overall integration.
![]()
More than anything else, Databricks has gained significant amounts of international attention — and, consequently, international success — for its distinctive pricing structure. As we will further explain below, Databricks essentially has a pay-as-you-go pricing model, meaning that enterprises that require more data storage will pay more, while enterprises with lesser data storage needs will pay less.
For many, this is considered a pricing model that is superior to other options, such as “pure” tiered pricing structures that charge their users a pre-determined flat monthly rate.
How Does Databricks Pricing Model Work?
To put it simply, Databricks uses a consumption-based pricing model. In other words, the more you “consume”, the more you will need to pay. There are plenty of consumption-based pricing models that Databricks can easily be compared to, such as your electricity or gas bill. Very few people pay flat rates for electricity—the more they use, the more they will pay, which is a very intuitive way to price things.

However, contrary to the electricity bill mentioned above, measuring a single use of “computation” is not always quite as easy to measure. Still, Databricks aspires to offer the most straightforward pricing model available and has developed a distinct computing unit known as “Databricks Unit” (DBU).
Before further explaining how Databricks users can calculate their expected bill, let’s take a closer look at the factors used to calculate DBU consumption.
How is DBU Consumption Calculated?
A Databricks Unit (DBU) represents how much computation is “consumed”, which is then billed on per-second increments of computation usage.
There are several factors that affect how many DBUs a given enterprise uses in an hour. The (arguably) most impactful factor is the sheer volume of data usage. The impact of volume (at least when compared to the other factors) is generally linear, meaning that computing 20 TB of data will cost about five times as much as computing 4 TB of data.
Additionally, the DBU calculation will also be influenced by both data velocity and data complexity.
In this context, the term “data velocity” is used to mean the frequency the pipeline is loaded. Some ETL pipelines operate using a continuous operating model, which, as you might expect, is the most expensive way to operate. On the other hand, pipelines that are only updated a few times per day (or even less) will have a considerably lower velocity and, as a result, will cost much less to use.
“Data complexity”, in this sense, represents how much work is taken to process a particular data set. If a data set has to undergo a complex process, such as deduplication or table upserts, that data will be considered much more complex than data that doesn’t.
As a result — as you might expect — small, periodic, and simple data aggregations will require the fewest DBUs. On the other hand, large, constant, and complex data aggregations will require the most DBUs and will increase costs. Of course, most data sets fall somewhere in between these two, which is why calculating DBUs is not always as intuitive as you might assume.
How is the Price of a Given DBU Determined?
While the factors used to calculate DBU consumption are universal, the rates paid to access DBUs can vary, depending on a variety of factors. Think of it this way—if someone living in Poland and someone living in the United States each uses 100 Kw of energy within a specific timeframe, these two people would almost certainly end up with differently valued energy bills.
The cost of using a given Databrick Unit is affected by many of the same factors. The location of the enterprise utilizing the platform will influence the cost of each unit. Additionally, the Cloud Service (Azure, AW, etc.) being used by the enterprise will also have an impact.
Within each Cloud Service provider, there will typically be several distinctive “tiers” that will further influence the price of a given DBU. For example, AWS has three distinctive tiers—standard, premium, and enterprise—that each have distinctive DBU prices. Most other major platforms also use a clear three-tier structure, though you’ll still find plenty of exceptions.
The final factor that can influence the price of a given DBU is the computation type. Computation types include jobs compute, SQL compute, all-purpose compute, and more.
Ultimately, there are several factors that affect how many DBUs an enterprise is using per hour, just as there are also affecting the price of utilizing a particular DBU. Nevertheless, the formula used to calculate total DBU expenses remains the same.
How to Calculate the Cost of using Databricks
In order to calculate the total cost of using Databricks (represented as “Cost”), you’ll need to be aware of the following factors: the number of Databricks units that are being used and the rate you are asked to pay for each Databrick used (which, as discussed, can vary).
After that, all you need to do is use the following formula:

As suggested, these factors can vary, so instead of offering a direct example, we will offer a brief example using arbitrary units (DO NOT use this example to represent the total cost accrued by any enterprise).
If the company uses 5000 Databricks and the rate they are paying per Databrick is $0.10, then the total cost accrued would be as followed:
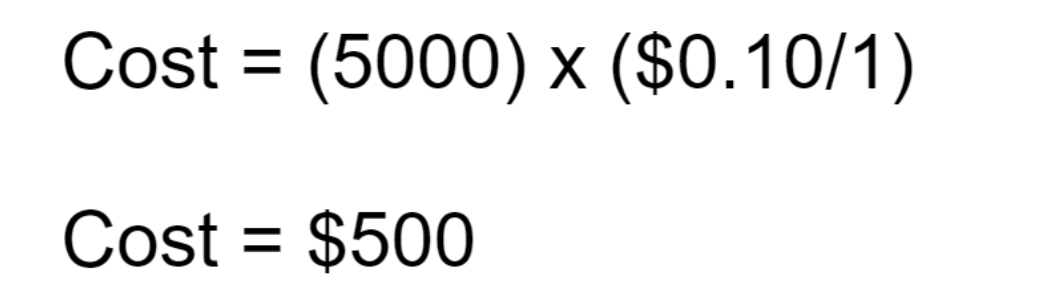
In other words, given the arbitrary figures mentioned above, the total cost of using Databricks would be $500. Over time, as Databrick consumption grows, the cost will increase at a linear rate, assuming there are no changes to the cost.
Benefits of the Databricks Pricing Model
While it might be considered somewhat novel within the broader data management industry.
The Databricks pricing model is straightforward and makes a lot of sense. If you are using electricity, naturally, you’d expect to pay more for using greater amounts of electricity. Similarly, someone buying five loaves of bread at the store can expect to pay five times as much as someone who bought a single loaf of bread.
As a result, the Databricks pricing model makes the processes involved in data storage, utilization, and transformation very predictable. For enterprises that are already operating at a large scale—or plan to increase their data utilization in the future—this is a pricing model that simply makes sense.
Taking Advantage of Databricks
In order to get the greatest possible benefit from using Databricks, it is important to understand how this platform is actually applied. If you recall, Databricks was developed by the founders of Apache Spark and has a direct connection with Apache Spark users. This means that any sort of program that runs on Apache Spark — including innovative platforms like Visual Flow — can be easily integrated into Databricks solutions.
In this context, it is important to note that Visual Flow is a zero-cost software (with subscription options) that can be directly connected to the Databricks system in case a low code component is required to write ELT jobs. It is also important to note that, in most cases, Databricks offers a free trial, allowing users to learn more about the system and determine whether or not using that platform meets their current needs.
Conclusion: How Has Databricks Helped Change the World?
At first, it might seem like Databricks (and the corresponding pricing system) isn’t doing anything particularly revolutionary—and that’s where you’d be wrong. While the so-called “pay-as-you-go” pricing model might seem intuitive at face value, the data management industry has taken a considerable amount of time to adopt this particular model. In other words, the simple formula mentioned above (where all you need to know are the rate and consumption volume) has changed the industry for the better.
FAQ
Databricks is a unified data analytics platform that allows organizations to process large amounts of data and extract insights from it. It is a cloud-based platform that combines features such as data engineering, machine learning, and data science. Databricks provides a collaborative environment for teams to work on big data projects, allowing for faster iteration and collaboration.
Databricks pricing is based on a consumption model, where users are charged based on the amount of processing power used. This is measured using Databricks Units (DBUs), which represent the processing power required to run specific tasks in the Databricks environment.
The pricing model is designed to be flexible, allowing users to choose the level of resources they need based on their specific use case. Users can also scale resources up or down based on their requirements, and they only pay for the resources they use.
The amount of DBUs consumed depends on several factors, including the type of workload being performed, the size of the dataset, the complexity of the queries, and the number of users accessing the platform.
For example, running a complex machine learning model on a large dataset will require more DBUs than running a simple query on a smaller dataset. Similarly, if multiple users are accessing the platform simultaneously, this can also increase the amount of DBUs consumed.
The price of a given DBU is determined based on the level of resources required to run a specific task in the Databricks environment. This is calculated based on the type of workload being performed and the resources required to complete the task.
Databricks offers different pricing tiers based on the number of resources required, with higher tiers offering more resources at a higher cost. Users can choose the pricing tier that best meets their needs, and they only pay for the resources they use.



























































Contact us