




Table of Content:
Table of Content:


Data scaling is crucial in the e-learning industry for analyzing and transforming large volumes of data, but it poses various challenges such as handling high volumes of data, maintaining data quality, privacy concerns, and handling the complexity of various data sources.
This guide outlines how advanced ETL systems and Visual Flow low code ETL platform can improve data scaling in the e-learning industry.
In the digital era, learning online has become more accessible – and more productive than ever before. As a result, the e-learning industry has continued to grow, both in the United States and elsewhere around the world.
However, as the industry has ambitiously expanded, many companies specializing in providing education services and online classes have run into a few obstacles. E-learning enterprises typically use large amounts of data – in order for these companies to thrive, they will need to learn how to effectively scale large amounts of data and manage it in an efficient way. Furthermore, being able to present clear and intuitive solutions will be essential for attracting new learners and students.
In most cases for all stakeholders it is absolutely critical to understand the processes of data extraction, transformation, and loading (ETL). In the end, that means any company that is hoping to sell its ETL-powered systems to an E-learner provider will need to be able to clearly illustrate how these processes work in a visually appealing way.
Let’s take a closer look.
Role & Volumes of Data for the Company in the E-Learning Industry
Data has become the lifeblood of the broader E-learning community. There is a wide variety of data used in this industry, including customer data, operational data, performance data, and more and how to scale data for the e-learning industry has become a widespread question among industry players.
But as these organizations scale, the consequences of having less-than-perfect data practices will compound. Eventually, excessive collections of data (only some of which will actually be useful) can hinder operational performance and stop organizations from achieving their desired goals.
Using ETL for is a practice that makes data scaling efforts much more efficient.
Key Challenges of Data Scaling for E-Learning Company
Here are just a few of the challenges involved in the data scaling process faced by one Visual Flow’s customer :
- Understanding the Product by End Users
Data scaling for e-learning companies is a complicated process. Even partners and c-level executives who consider themselves tech-savvy will likely need help from technical experts to have the processes presented to them in a clear, understandable way. And if sales people can’t understand or clearly present the product to those who make buying decisions, they will be much less likely to achieve their goals.
- Coordinating Schedules
Many data engineers have very busy schedules. If it takes several weeks to actually schedule and prepare customer meetings, the E-learning company will end up losing revenue. Simple and intuitive ELT solutions can be added-value to sales people and provide them with intuitive tools that can convince new customers to make buying decision.
- Need for New Code
New code is needed every time a new customer is onboarded, which will require both time and effort. In the end, the client decided to look for a low-code alternative to shorten the sales cycle.
- Time-Consuming
Typically, it takes about 3-4 days to create the custom ETL pipeline depending on the work requirements, as well as test and deploy that code in a new environment. Actual timelines will vary by project.
Visual Flow is a low code ELT solution with an easy-to-use drag-and-drop interface compatible with Apache Spark, Kubernetes, and Argo Workflows.
Is It Possible to Solve the Scaling Problem without a Professional ETL Tool?
One can believe that It is possible to solve the scaling problem without a professional ETL tool. The solution would typically involve using programming languages like SQL, Python, Java or Scala to write custom scripts that can extract, transform and load data in the required format.
At first, some e-learning companies might be resistant to new data scaling solutions, such as those provided by an ETL tool.
However, using a professional ETL tool can simplify the process and save time. ETL tools that use Apache Spark behind the hood are designed specifically to handle large-scale data integration, making it easier to manage complex data transformations and load data into multiple data sources with speed that in minutes and not hours.
Ultimately, the decision to use an ETL tool or not will depend on the size and complexity of the data, the available resources, and the specific requirements of the project.
So trying to scale increasingly large bodies of data without an ETL tool can result in a lot of problems for fast-growing enterprises.
Without the right systems and processes in place—as well as a team of data engineers that truly understands what they are doing—large amounts of data could end up getting lost or compromised. And even if the data isn’t permanently lost, the data scaling process could still be hindered or otherwise distorted.
Why was that Approach Insufficient?
When insufficiently executed, there are many steps of this process that will end up taking much longer than actually needed. A prospective client could be very interested in the service being offered but until they understand what they will receive, they won’t want to make any formal commitments.
Usually, this means that the tech sales team will need to prepare a demo—a process which, when done on their own, could potentially take a week or more to complete. Additionally, training the sales team to competently work with a traditional ETL is a process that can take as long as 2-3 months, which, in the end, will delay revenue streams even further.
That is why many organizations in the E-learning industry have begun looking for alternative solutions, such as those presented by the Visual Flow.
Successive Stages - How to Scale Data for E-Learning Company
Implementing a new data scaling system isn’t something that happens overnight. However, the differences between an efficient deployment and an inefficient deployment can be profound and can have a significant impact on the company’s bottom line.
While the exact timeline will vary depending on the client, the process can usually be divided into a few distinct steps, including the discovery sessions, software deployment and setup, re-designing and redeveloping the ETL pipeline, testing, and — finally — hypercare.
- Discovery Session
The “Discovery Session” is the first step of the process where the ETL service provider and data engineers learn as much as they possibly can about their prospective partner and prepare for the future of the project. This typically involves a variety of different tasks, including defining the migration plan, identifying limitations, and analyzing various feasibilities. In most cases, the discovery session can be managed completely remotely and will take about two days.
- Software Deployment and Setting Up
Once the discovery session has been completed, the next step in the process will be to set up the software and actually deploy it. The dynamics involved during this step of the process will depend on what (if any) data scaling and management tools have already been implemented. The ETL will also be configured and customized, as needed.
The professional service team at Visual Flow can provide assistance with installing Kubernetes, Apache Spark, and Argo workflows (workflow orchestration engine for Kubernetes) either on-premises or on cloud platforms such as Azure or AWS.
- Re-Design and Develop ETL Pipelines
As soon as the basic infrastructure has been established, the company will then have the opportunity to develop (and subsequently redevelop) pipelines that can help address their specific data scaling needs.
It will be important to define several different components of the project, including staging requirements, integration approaches, transformations, ETL jobs, and general pipeline structures. Typically, this part of the process takes about two weeks.
- Test
Next, the Visual flow team will carefully test every component of the data infrastructure, including all pipelines. If the tests reveal any sort of errors or inefficiencies, the team will then carefully adjust and test the pipelines again.
Eventually, the end goal is to have ETL jobs and pipelines that do not have any interruptions and can process data in just minutes.
- Hypercare
Finally, the “hypercare” component of the process is the stage where the ETL data structure will continue to be carefully managed. This stage is crucial for successful data scaling for any e-learning company
This step will usually require making minor changes, providing ongoing support, and carefully documenting all ETL best practices.
Real Case of Data Scaling for E-Learning Company by Visual Flow
Visual Flow is one of the most useful open source tools that can be used by a wide variety of developers without the need for learning a programming language (such as Scala).
Who is This Client?
In this particular case study, the client was a US-based startup that currently provides a variety of education technology services.
These include LMS (learning management systems), SIS (student information systems), CRM (customer relationship management), and more. Each of these services helps make it much easier for educational institutions to manage large amounts of data and provide insights.
What was the Trigger for the Company to Contact Us?
Prior to contacting Visual Flow team, the client was experiencing a wide array of problems. Their previous process was highly technical, inaccessible, and would often take considerably longer than necessary to actually implement. After an internal analysis, the company decided that switching to a much more intuitive low-code ETL tool would be the ideal solution.
The client also had a few structural needs, such as needing to deploy the ETL tool on AWS Kubernetes cluster, where they had already established a SaaS presence. However, they also wanted flexibility, efficiency, and a reasonable price point—something that typical proprietary ETL solutions like Pentaho, IBM Data Storage, AWS Glue usually cannot provide.
The client was growing tired of losing potential customers to their competitors, which is why they ambitiously pursued change. In the end, Visual Flow’s distinctive combination of affordability, scalability, reliability, and better scheduling functionality helped it become a favorite product among data engineers.
The Solution We Provided
In the end, Visual Flow professional services team provided the client with support and guidance for the free, open-source components of the platform, along with an additional scope of ongoing support. One of the most important goals when making the switch was to ensure that the sales team could easily showcase—visually—to prospective partners how all data will be gathered, stored, transformed, and securely managed.
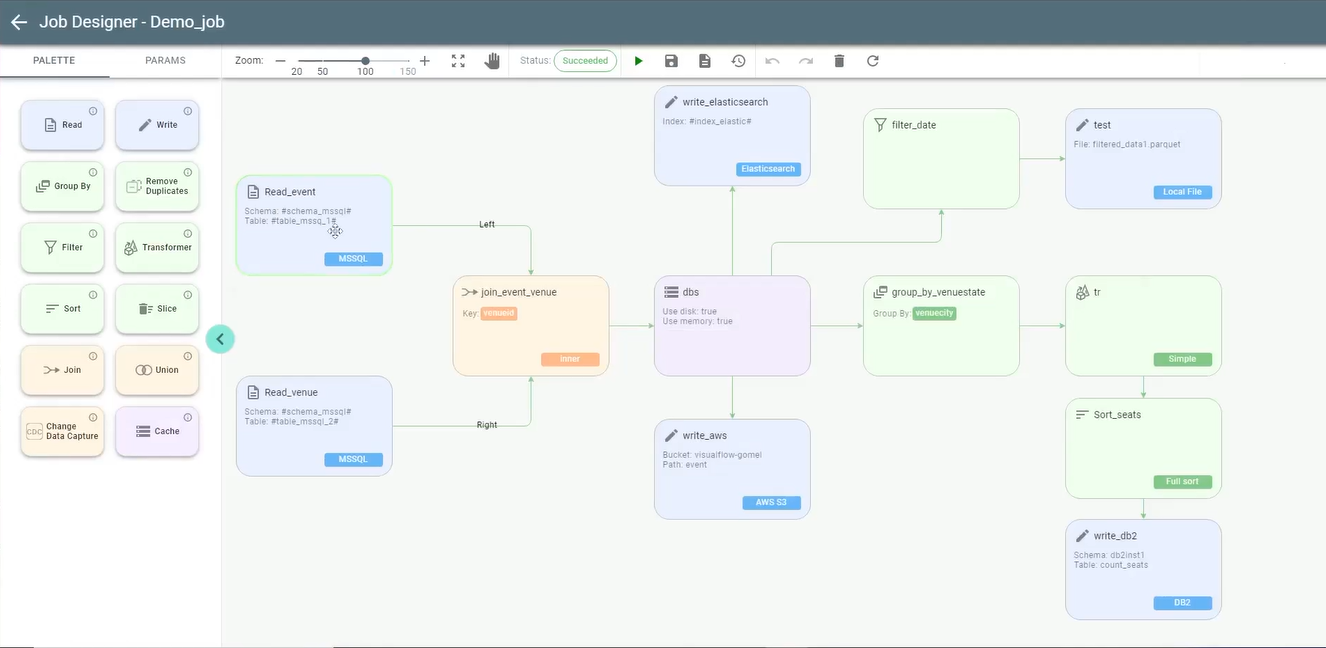
Having a low-code platform made the process much more accessible than it otherwise would have been. Additionally, some of the data engineers who were initially skeptical about the project are now reporting that they greatly prefer the new system. The relationship with Visual Flow continues to this day.
Results
Since implementing this new system, the client has been able to use low-code presentations to more efficiently attract clients. The sales team has also considerably improved its outcomes, such as being able to explain the data process to prospects with greater clarity. In the end, the company is in a much better position to grow and achieve its goal.
Learn more about how Visual Flow can help you achieve your goals.
Conclusion
Data scaling in the e-learning industry is incredibly important. In order to succeed in this competitive space, enterprises will need to distinguish themselves from their competitors by implementing optimized data scaling solutions. By working with the Visual Flow team, these companies can achieve better results.
FAQ
The best way to scale data is through the use of a customizable, low-code platform, such as Visual Flow.
As suggested, while the exact timeline will vary depending on the client, the process can usually be divided into a few distinct steps, including the discovery sessions, software deployment and setup, re-designing and redeveloping the ETL pipeline, testing, and—finally—hypercare.
When it comes to data scaling in e-learning, companies will need to consider several factors, such as ROI and scalability, accessibility, the platform they are using, and efficiency, as well as their target market.



























































Contact us